In this project, I’m going to show you how my friend and I scraped data from Instagram’s (somewhat) public API and how we used this data to gain insights about the most popular locations to take pictures in a given area.
Find repo here.
Motivation
One of my close friends really likes taking pictures. One thing I never realized was how hard it was to find good places to take pictures, especially in Tallahassee, FL (my hometown).
Even with the power of the internet, it seems like we never really get what we’re looking for. Maybe Yelp might suggest a museum, or a restaurant with a cool balcony, but the problem is that Yelp and other sites are confined to buildings or parks and, in general, things with names.
What we really want is that street corner or parking garage that everyone seems to discover on their own. The one you can only get by checking their tagged location on their Instagram post and finding from walking around the general vicinity.
A second, bigger problem is that we don’t know what to expect from a suggestion from Yelp and friends. We don’t have a good understanding of the type of pictures we can take, etc.
For example, if Yelp recommended a guitar shop to take pictures, what we really want is the knowledge that there’s a cool mural on the wall of the shop:
 |
|---|
| This is actually the wall to a guitar shop in my city |
Finally, Instagram and friends don’t really make discovering locations very easy. They don’t offer a way to heat-map where pictures are taken which makes finding things in the area hard.
In this project, we’ll solve try to solve these three problems.
Summary of Problems
- We want to know of popular locations to take cool pictures.
- We want to know what kind of pictures are taken at a location in advance.
- Getting useful information from Instagram is hard/time consuming.
Key Assumptions
The first assumption that’s going to be made is that when people tag locations, they tag the nearest location to where they took the picture. Going back to the guitar shop example, maybe they took a picture in front of the mural, but they’ll end up tagging the guitar shop.
Thus, it’s safe to trust that Yelp and friends kind of know what they’re doing when they make recommendations, but to gage a location’s picture-worthiness, we still want to know how many pictures are taken at that location.
Project Flow
Note: The focus will be on locations in Philadelphia since I ultimately did this for a school project.
- Scrape a bunch of location names (e.g. Railroad Square or Philadelphia Art Museum) in Philadelphia from tourist sites and sites compiling best places to take pictures.
- Match this location to a tagged location in Instagram and determine how popular (i.e. how many pictures were taken) at this location.
Step 1
Doing the first is surprisingly really easy. Using chrome extensions like Web Scraper, we can quickly compile excel-like data from sites like Yelp, VisitPhilly, Narcity, etc. We can quickly get lists of location names from Yelp like:
| name | rating | event_type | address |
|---|---|---|---|
| Arden Theatre Company | 4.5 | Performing Arts | 40 N 2nd St |
| Washington Square Park | 4.5 | Parks | W Washington Sq |
| J&J Studios | 5 | Session Photography | Serving Philadelphia and the Surrounding Area |
Step 2
Now, once we have a bunch of semantic location names, we want to match these names with the url of tagged locations on Instagram (i.e. the second part). Just for reference, here’s an example of a tagged location:
https://www.instagram.com/explore/locations/214228753/philadelphia-pennsylvania
Unfortunately, Instagram deprecated their public API in 2018, so this is where things get annoying.
Instagram’s API doesn’t allow for location based queries (i.e. by address or lat/long), so the best way I found to get this information is by literally mimicking a user and searching for a location name in the search bar and getting the top search result.
Python Selenium is the perfect for this. Selenium is a python package that lets you mimic the browser and automatically interact with sites in a certain way. Here’s an example showing how to login to Instagram’s login page with a username and password:
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
username_str = "INSERT_USERNAME"
pwd_str = "INSERT_PASSWORD"
driver = webdriver.Chrome(
executable_path="/Users/karthikmacherla/chromedriver")
driver.get("https://www.instagram.com/")
# enter username field
username = WebDriverWait(driver, 20).until(
expected_conditions.presence_of_element_located((By.NAME, "username")))
passwd = WebDriverWait(driver, 20).until(
expected_conditions.presence_of_element_located((By.NAME, "password")))
username.clear()
username.send_keys(username_str)
passwd.clear()
passwd.send_keys(pwd_str, Keys.RETURN)
Since the search bar only appears after we login, we have to first login, wait for the page to load, then find the search bar element using selenium query tags. I found the div class to be some random string XTCLo. We get the bar like this:
# Wait for page to load and send search query
search_bar = WebDriverWait(driver, 20).until(
expected_conditions.presence_of_element_located((By.CLASS_NAME, "XTCLo")))
Now, to find the best tagged location, we search for a location name in the search bar and then sift through to find the first result that’s a location. This has to be the most fitting location. Note that just like before, we have to wait some seconds in order for the search results to appear. Here’s is our find_location_url function for a query:
def find_location_url(driver, search_bar, query):
"""
Finds the most relevant location corresponding to a search query
- search_bar = element
- query = the string
"""
# make sure there aren't previous search results
search_bar.clear()
try:
# press the clear search results button
x_button = driver.find_element_by_class_name("aIYm8")
x_button.click()
except Exception:
pass
search_bar.send_keys(query)
results = WebDriverWait(driver, 10).until(
expected_conditions.presence_of_element_located((By.CLASS_NAME, "fuqBx")))
links = results.find_elements_by_tag_name("a")
print(f"Results: {len(links)} found")
# get the first result i.e. the most relevant one that corresponds to a location
res = ""
for link in links:
absolute_url = link.get_attribute('href')
if absolute_url.startswith("https://www.instagram.com/explore/locations"):
res = absolute_url
break
search_bar.clear()
return res
Awesome! We’re able to do this on every location name we get from step 1, and we end up with a bunch of tagged location urls:
import pandas as pd
inp_data = pd.read_csv('./inputdata.csv')
for i, name in enumerate(inp_data['Name']):
url = find_url(driver, search_bar, name)
inp_data.at[i, 'Instagram URL'] = url
But how do we get the number of posts at a tagged location? For each Instagram tagged url, adding ?__a=1 at the end gives us a bunch of public information in the form of JSON. For example, for Philadelphia (https://www.instagram.com/explore/locations/214228753/philadelphia-pennsylvania/?__a=1):
{
"graphql":{
"location":{
"id":"214228753",
"name":"Philadelphia, Pennsylvania",
"has_public_page":true,
"lat":39.9527,
"lng":-75.1651,
"slug":"philadelphia-pennsylvania",
"blurb":"",
"website":"http://www.phila.gov/",
"phone":"","primary_alias_on_fb":"",
"address_json":"{\"street_address\": \"\", \"zip_code\": \"\", \"city_name\": \"Philadelphia, Pennsylvania\", \"region_name\": \"\", \"country_code\": \"US\", \"exact_city_match\": true, \"exact_region_match\": false, \"exact_country_match\": false}",
"profile_pic_url":"https://scontent-dfw5-2.cdninstagram.com/v/t51.2885-15/e35/c0.179.1440.1440a/s150x150/161704193_3809484709275629_6812827654887879071_n.jpg?tp=1&_nc_ht=scontent-dfw5-2.cdninstagram.com&_nc_cat=1&_nc_ohc=EnsG77cl_dMAX-iu-4e&ccb=7-4&oh=6288b1cbc8901dc82c8abb7812b0fdde&oe=60806576&_nc_sid=b2a057",
"edge_location_to_media": {
"count":10310101,
"page_info":{
"has_next_page":true,
"end_cursor":"2533339397788366529"
}
}
}
}
}
Thus, all we need to do is get the JSON for each link, and extract the count from each url.
def get_json_info(driver, url):
driver.get(url)
content = driver.find_element_by_tag_name('pre').text
json_data = json.loads(content)
json_data = json_data["graphql"]["location"]
lat = json_data["lat"]
long = json_data["lng"]
website = json_data["website"]
profile_pic_url = json_data["profile_pic_url"]
count = json_data["edge_location_to_media"]["count"]
return {
"count": count,
"lat": lat,
"long": long,
"website": website,
"pic": profile_pic_url
}
for i, url in enumerate(inp_data['Instagram URL']):
if url != "":
modified_url = url + "?__a=1"
print(modified_url)
info = get_json_info(driver, modified_url)
inp_data.at[i, 'Count'] = info["count"]
inp_data.at[i, 'Longitude'] = info['long']
inp_data.at[i, 'Latitude'] = info['lat']
inp_data.at[i, 'Website'] = info['website']
inp_data.at[i, 'Profile Pic'] = info['pic']
inp_data.to_csv("output.csv")
Summary
Putting the whole process together, we get count information, relevant pictures, and exact locations with just a location name! What can we do with this? We can make cool maps like this (check out the interactive version here):
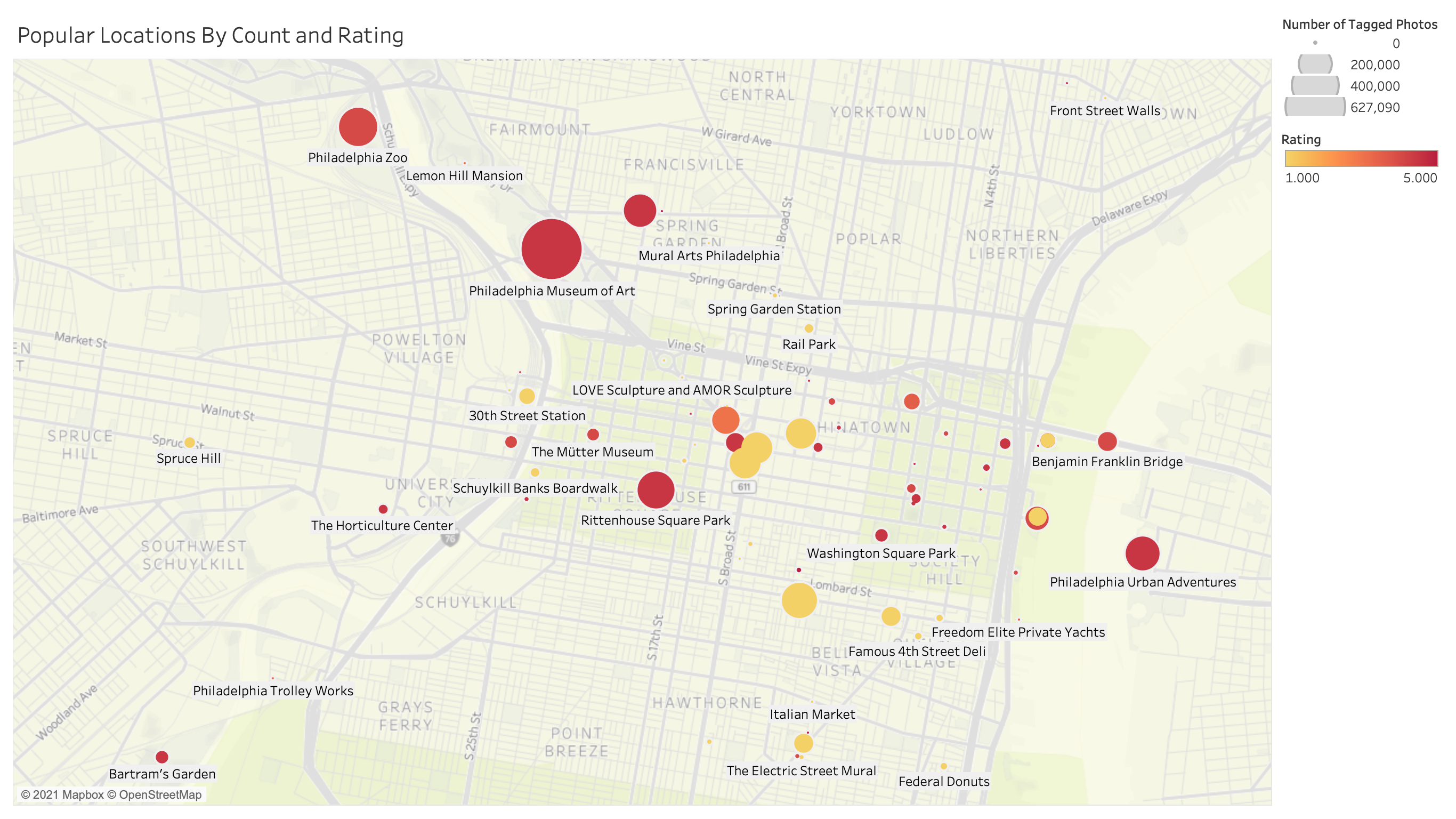
And discover that certain burrows in Philadelphia are much better to explore on foot than others:
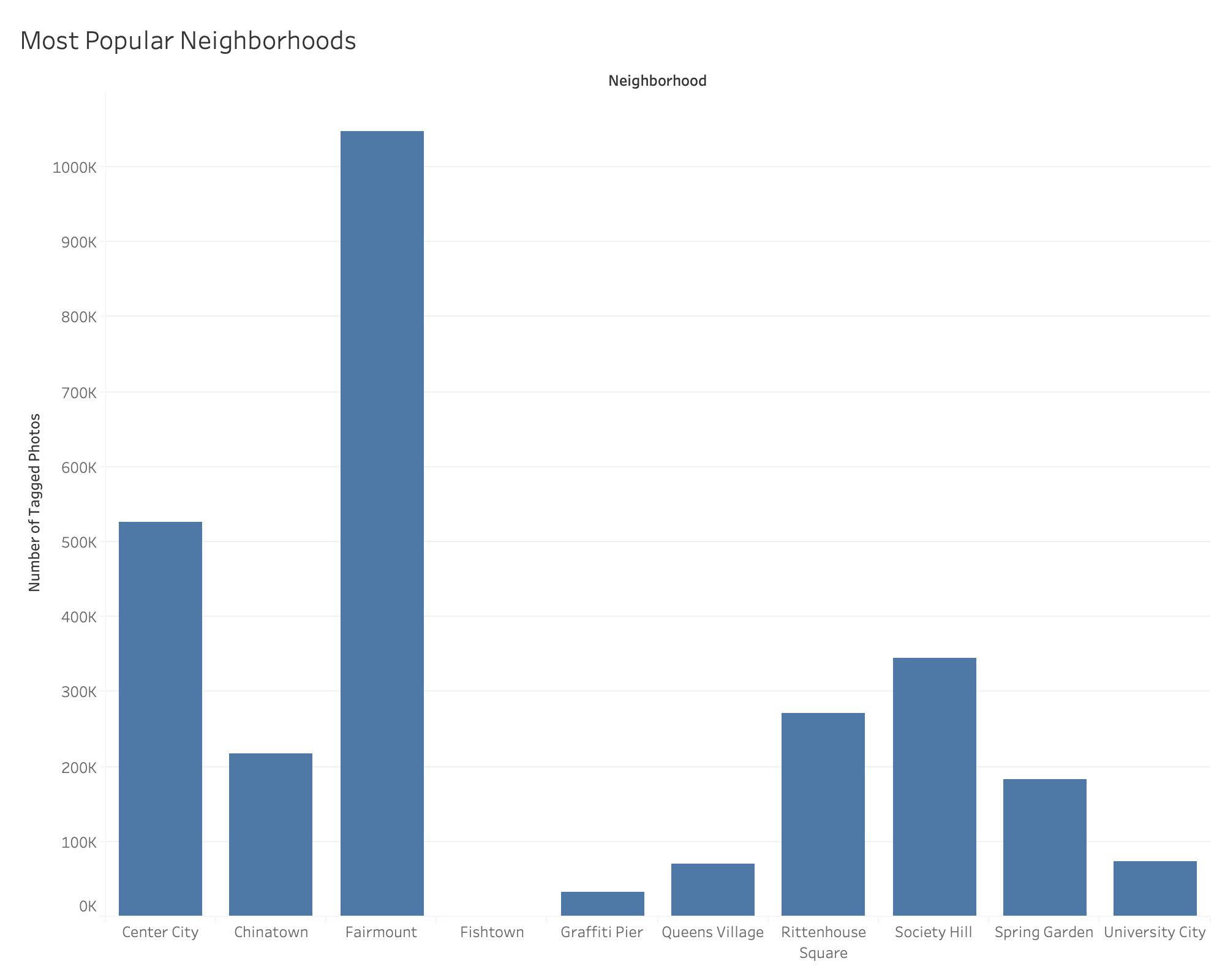
And that there are a bunch of places that people are discovering but aren’t showing well known tourist locations:
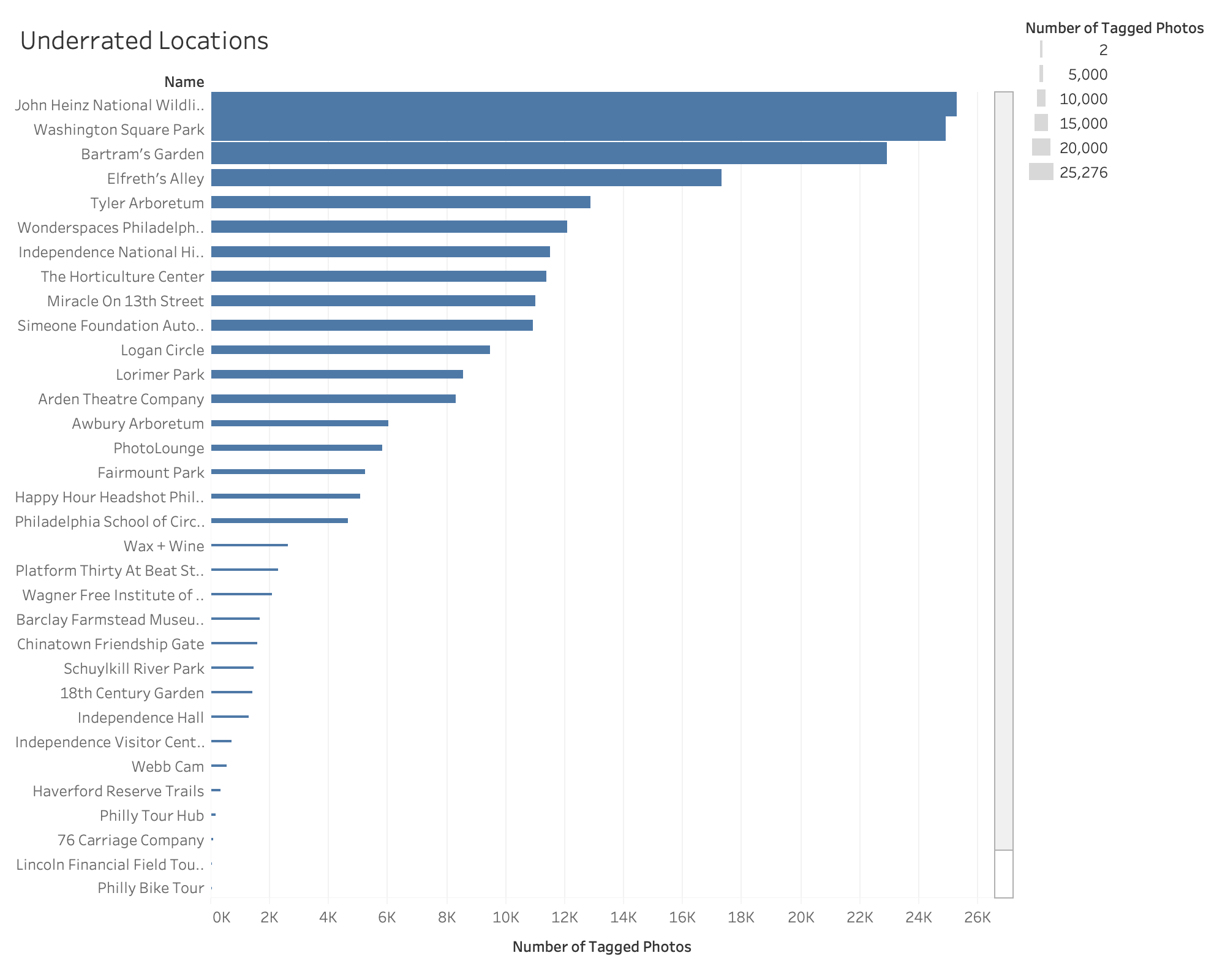
Feel free to check out the code and use it to find what’s new and undiscovered around you!
Reflection
Overall, super exciting project. Selenium is a game changer. As a programmer, I’ve always felt limited by what an API allows me to do, but here is an example of where we went out and got data even when it wasn’t formally published or maintained.